Parallelism Abstraction Layer
In this page, we will explain how we design and implement NAND flash array model, named Parallelism Abstraction Layer - PAL.
PAL provides abstract class, so you can implement your own NVM latency model by inherit the class.
By default, we provide PALOLD, derived from SimpleSSD 1.0.
Abstract Class
AbstractPAL class is defined in pal/abstract_pal.hh.
It defines three virtual functions (+ three virtual functions derived from StatObject).
Current PALOLD does not supports advanced NAND operations, such as copyback, read/write cache, multi-plane and so on.
We will update AbstractPAL when we replace PALOLD with updated PAL.
PALOLD
Original PAL source code derived from SimpleSSD 1.0 can be found at pal/old directory.
PALOLD class defined in pal/pal_old.hh wraps all PAL codes.
Original PAL supports per-die/per-plane statistics but current PALOLD disabled them (calculated, not printed).
If you need such detailed statistics, you can modify PALStatistics.* files inside the pal/old directory.
Source codes inside pal/old are quite complicated and hard-to-read.
You may not want to modify them.
Here is brief explanation of each files:
Latency*: These files calculate NAND page offset (LSB/CSB/MSB) and consumed energy.PAL2_TimeSlot.*: These files define timeslot, the unit of flash transaction scheduling.PALStatistics.*: These files calculate all statistics of all NAND flash array components.PAL2.*: These file definesPAL2class, top class of PAL.
Parallelism and Page Allocation
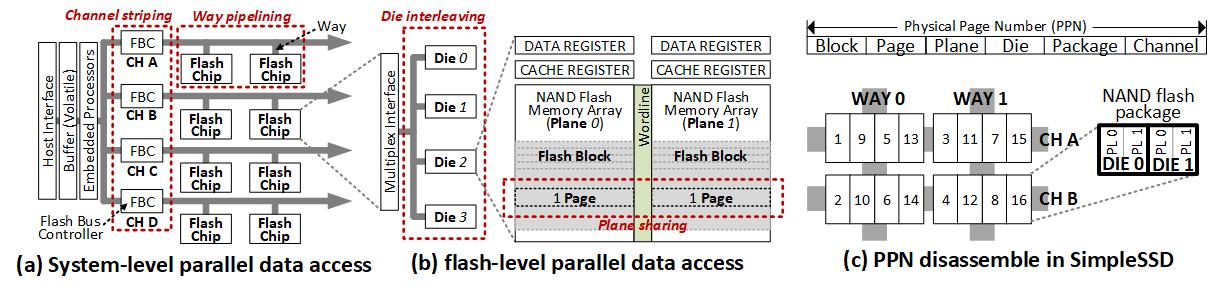
Different level of parallelism
In order to improve the SSD performance, there are four different level of parallelism methods which are system-level parallel access methods (channel striping and way pipelining) and flash-level parallel access methods (die interleaving and plane sharing). As shown in above Figure, an I/O request is striped over multiple channels (channel striping). Although an I/O request cannot be perfectly striped in parallel over multiple-ways since the ways share the channel, individual NAND flash chip (package) can work simultaneously due to NAND flash transaction’ multiple phases (way pipelining). Not only for the system-level parallelism but the striped or pipelined I/O request can be further interleaved within a NAND flash chip (die interleaving). In addition, multiple planes simultaneously work using shared wordline(s). Note that different vendors use different naming rules for parallelisms. Channel striping (= superblock, parallel-request scheme), way pipelining (= gaining, micron-style interleaving, package interleaving), die interleaving (= channel interleaving, inter-plane interleaving, interleaved die operation, bank interleaving), and plane sharing (= micron-style superblock, plane-pairs, super-page, multiple-mode operation).
To enable the different level of parallelisms when the flash translation layer (FTL) allocates a page, SimpleSSD provides configuration parameters, SuperblockSize and PageAllocation which configures size of super block and determines physical page address disassemble orders.
Simplified Timeline Scheduling

Different level of parallelism
As shown in Figure a, NAND flash’ PROGRAM/READ latency model is complicated due to multiple cycle types such as command, address, data input, and output. In order to simplify the traditional SSD operations, SimpleSSD models the latency with three categories, pre-dma, mem-op, and post-dma. Pre-dma consists of opcode, address, READ operation data, and command which should be transferred before the flash memory operation. Thus, pre-dma can be configured with page size, DMA frequency, command and address delay parameters. Mem-op is a latency of NAND-flash operation itself (READ/PROGRAM). It can be decided by considering NAND flash types (SLC/MLC/TLC), operation types (READ/WRITE), and page types (MSB/CSB/LSB). In contrast to pre-dma, post-dma includes WRITE operation data, and command which should be transferred after NAND-flash memory operation.
Since the pre-dma and post-dma consume CHANNEL resource and mem-op consumes DIE resource, there can be conflicts as shown in Figure b and c. If the two request are issued to pages which use same channel 0 and different die 0 and 1, there are pre-dma and post-dma conflicts due to channel sharing. In addiion, if two requests use same channel and die, there are not only for pre-dma and post-dma conflicts but also the mem-op conflict due to die sharing.